
 Hyojin Kim's blog
Hyojin Kim's blog
R-CNN/Fast R-CNN/Faster R-CNN/SSD
02 Mar 2020 | Deep learning Object detection R-CNNR-CNN/Fast R-CNN/Faster R-CNN/SSD
전문은 https://seongkyun.github.io/papers/2019/01/06/Object_detection/ 을 가져왔다. 초반에 공부하기 매우 좋은 게시글이며, 해당 저자의 블로그에 들어가보면 더 풍부한 내용을 얻을 수 있다.
Introduction

- 객체 탐지(Object detection)은 사진처럼 영상 속의 어떤 객체(Label)가 어디에(x, y) 어느 크기로(w, h) 존재하는지를 찾는 Task를 말한다.
- 수 많은 객체 탐지 딥러닝 논문들이 나왔지만, 그 중 Base가 될 법한 기본적인 모델들인 R-CNN, Fast R-CNN, Faster R-CNN, 그리고 SSD에 대해 알아본다.
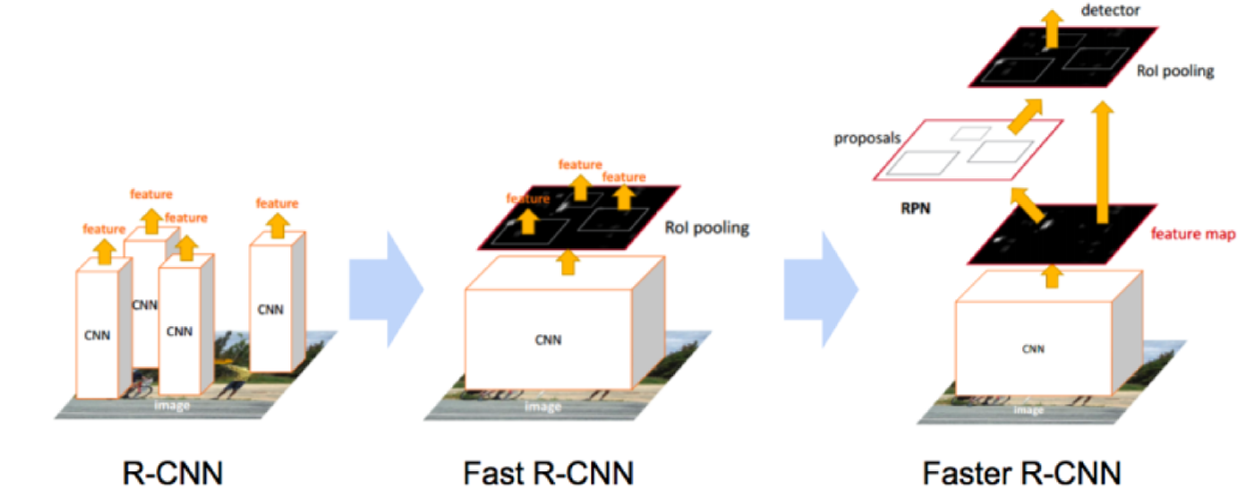
R-CNN
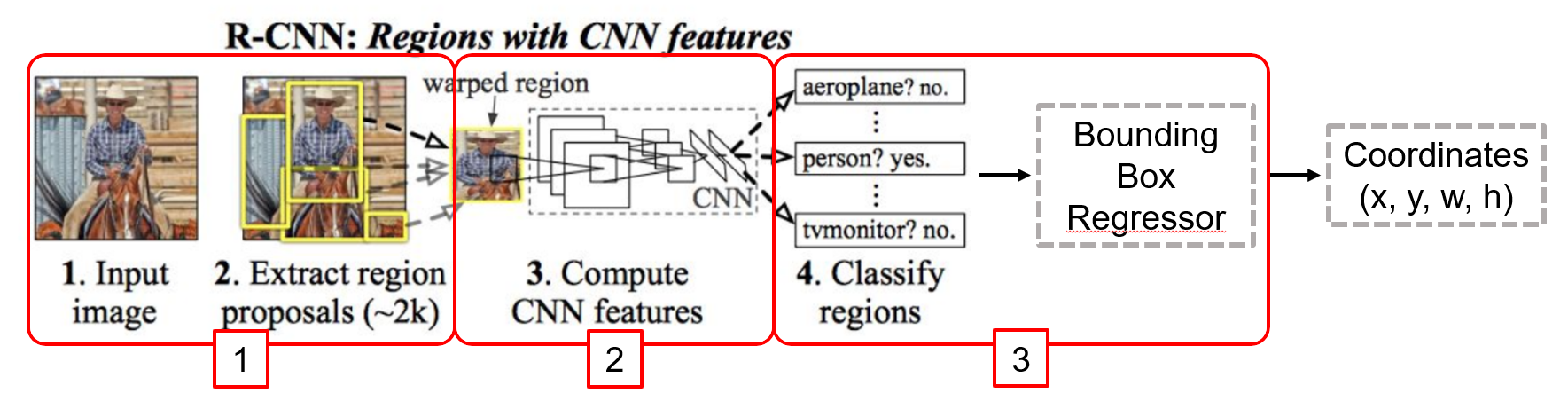
- Hypothesize Bounding Boxes (Proposals)
- Image로부터 Object가 존재할 적절한 위치에 Bounding Box Proposal (Selective Search)
- 2000개의 Proposal이 생성됨.
- Resampling pixels / features for each boxes
- 모든 Proposal을 Crop 후 동일한 크기로 만듦 (2242243)
- Classifier / Bounding Box Regressor
- 위의 영상을 Classifier와 Bounding Box Regressor로 처리
- 하지만 모든 Proposal에 대해 CNN을 거쳐야 하므로 연산량이 매우 많은 단점이 존재
Fast R-CNN
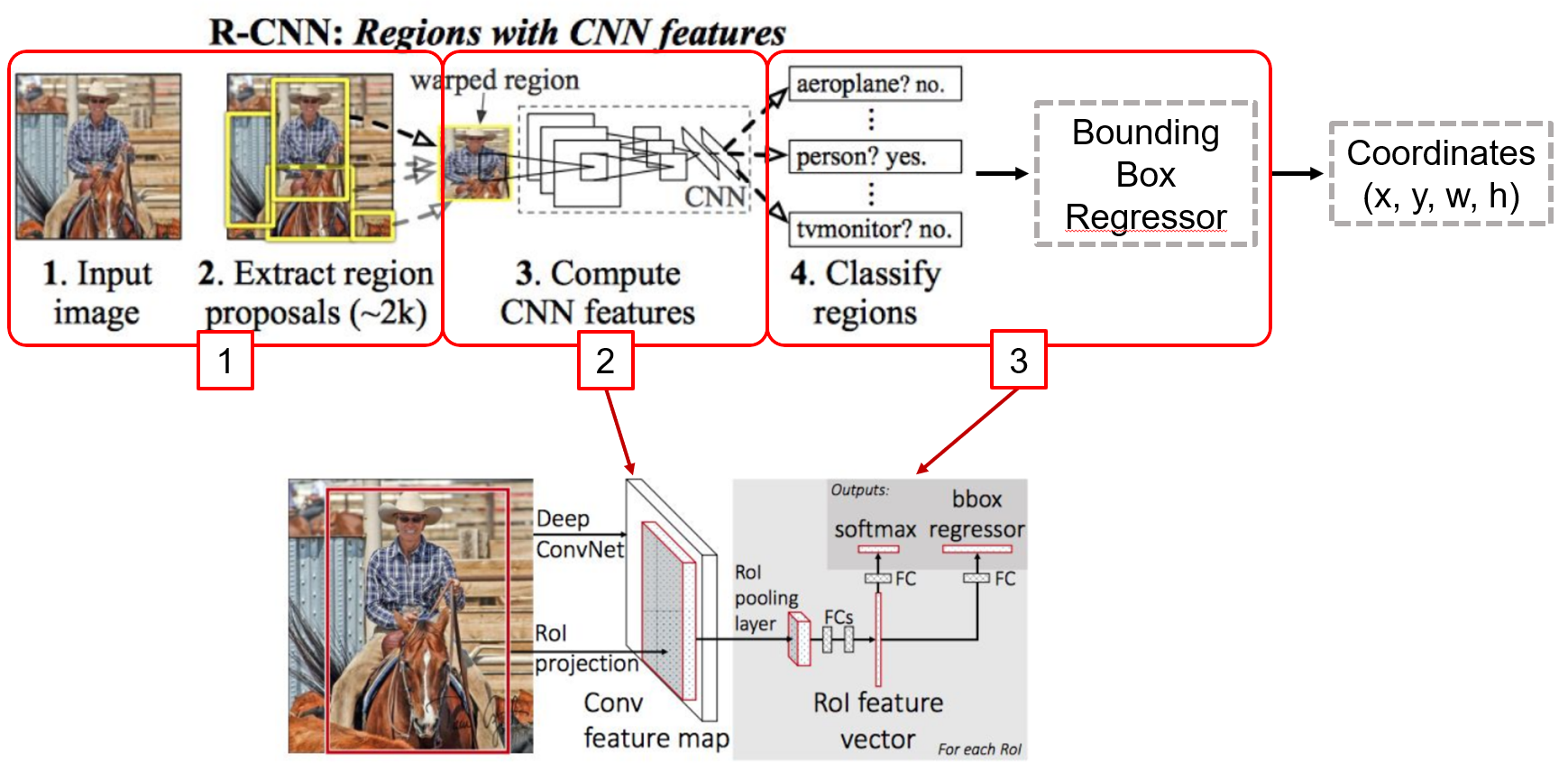
- Fast R-CNN은 모든 Proposal이 네트워크를 거쳐야 하는 R-CNN의 병목(bottleneck)구조의 단점을 개선하고자 제안 된 방식
- 가장 큰 차이점은, 각 Proposal들이 CNN을 거치는것이 아니라 전체 이미지에 대해 CNN을 한번 거친 후 출력 된 특징 맵(Feature map)단에서 객체 탐지를 수행

- R-CNN
- Extract image regions
- 1 CNN per region(2000 CNNs)
- Classify region-based features
- Complexity: ~224 x 224 x 2000
- Fast R-CNN
- 1 CNN on the entire image
- Extract features from feature map regions
- Classify region-based features
- Complexity: ~600 x 1000 x 1
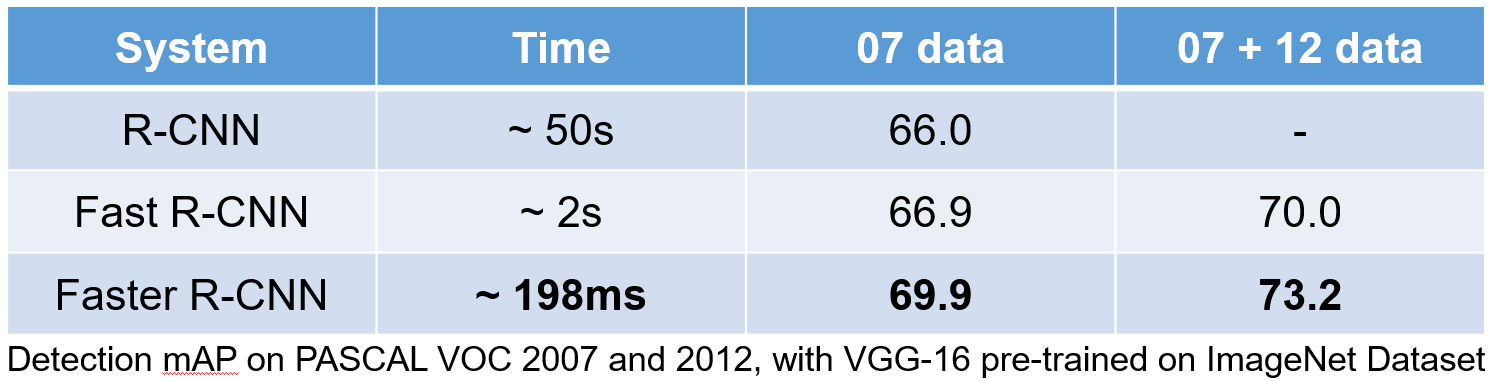
- ~160x faster than R-CNN
- 하지만 Fast R-CNN에서 Region Proposal을 CNN Network가 아닌 Selective search 외부 알고리즘으로 수행하여 병목현상 발생
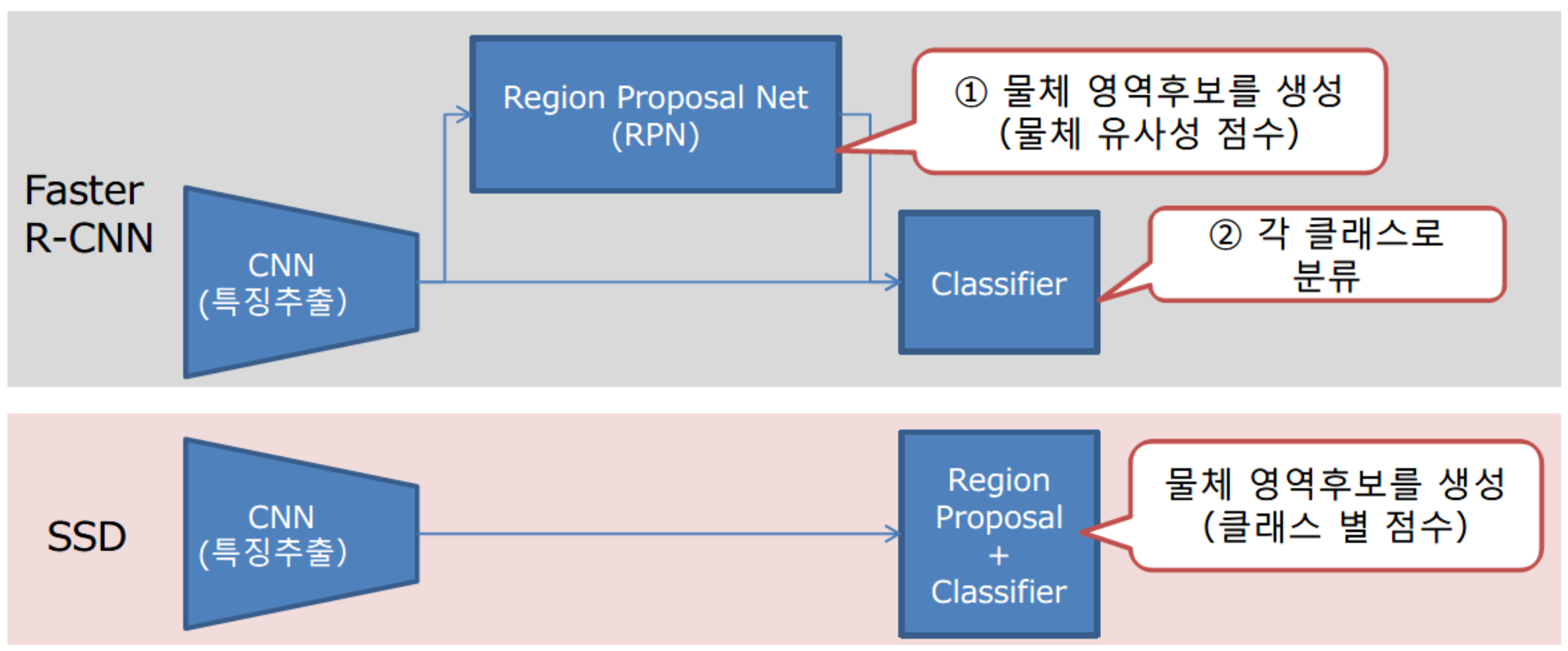
Faster R-CNN
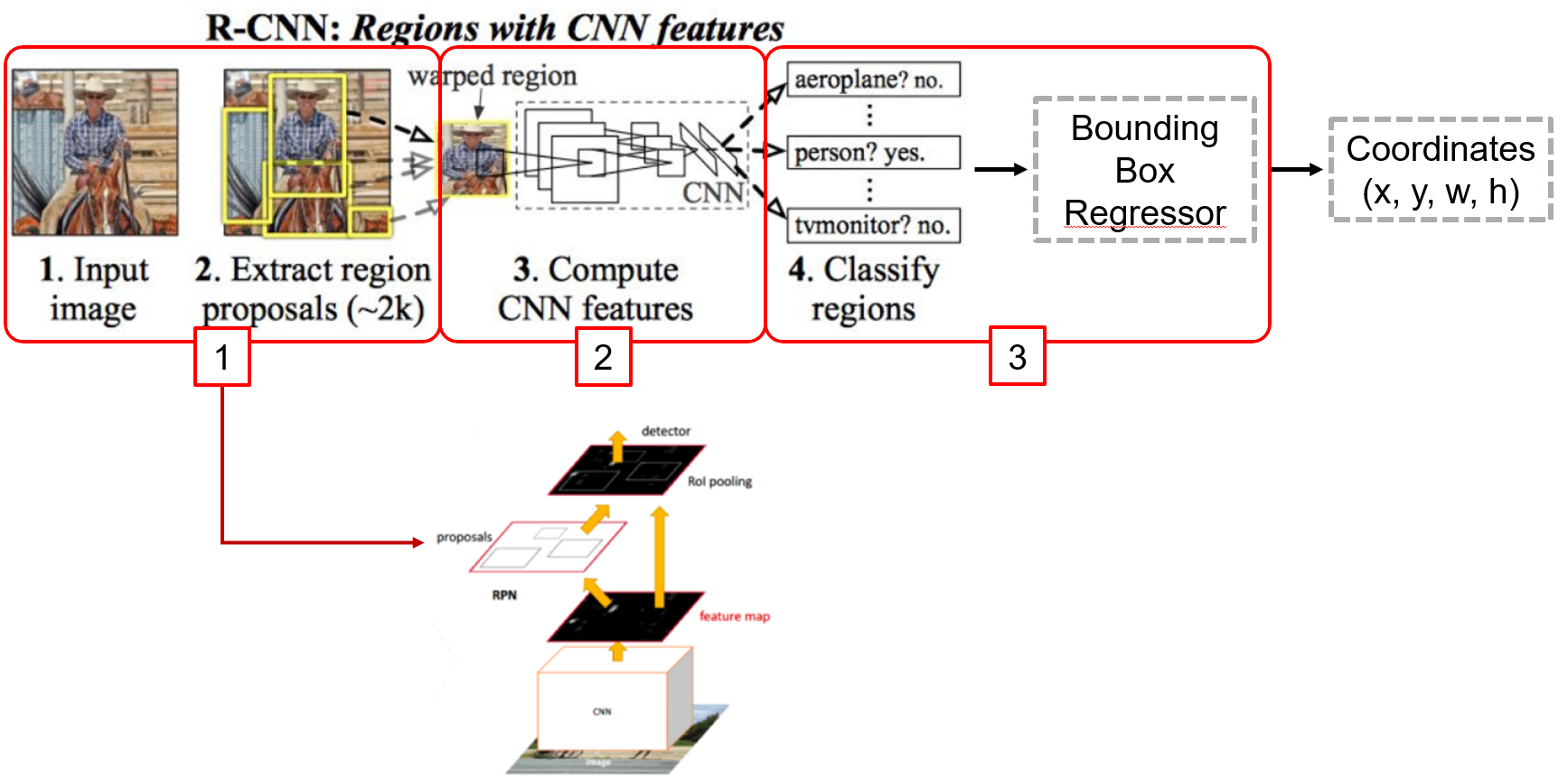
- Region Proposal을 RPN이라는 네트워크를 이용하여 수행(병목현상 해소)
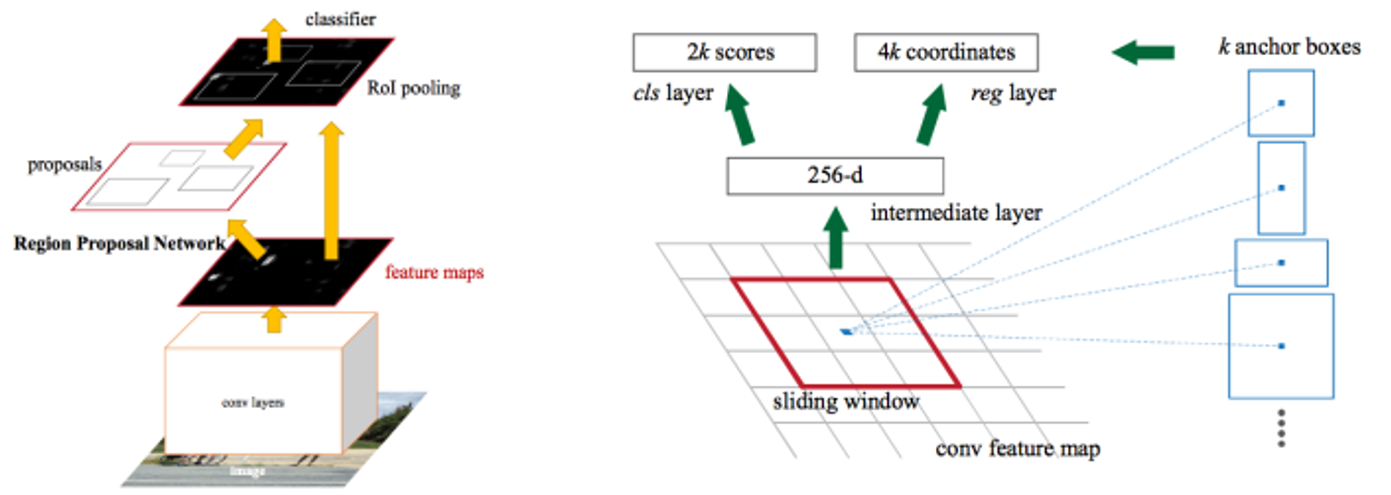
- Region Proposal 단계에서의 bottleneck 현상 제거
- 해당 단계를 기존의 Selective search 가 아닌 CNN(RPN)으로 해결
- CNN을 통과한 Feature map에서 슬라이딩 윈도우를 이용해 각 지점(anchor)마다 가능한 바운딩 박스의 좌표와 그 점수를 계산
- 2:1, 1:1, 1:2의 종횡비(Aspect ratio)로 객체를 탐색
Single Shot Multi-box Detector (SSD)
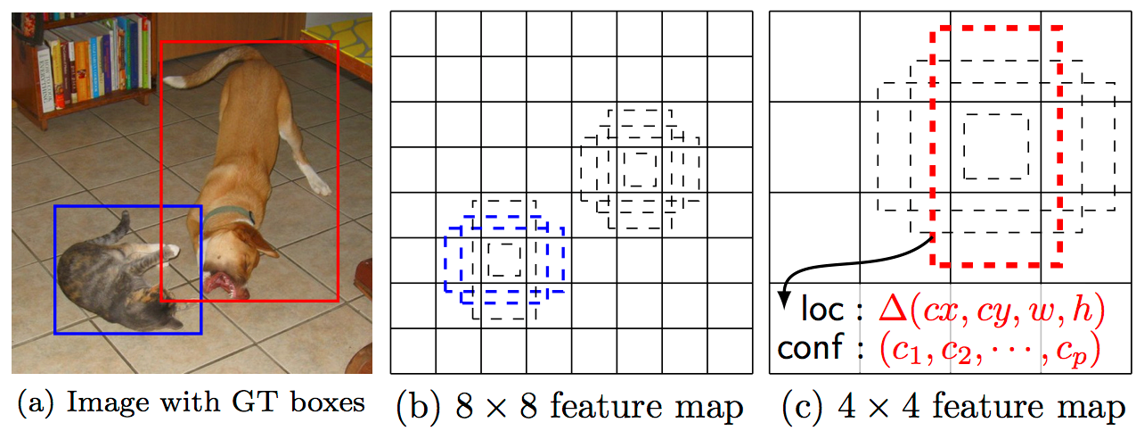
- Multi-scale feature maps
- 크기가 다른 객체 검출을 위한 다양한 크기의 Grid cell을 사용
- 검출기는 Grid cell과 크기가 비슷한 객체를 찾도록 학습됨
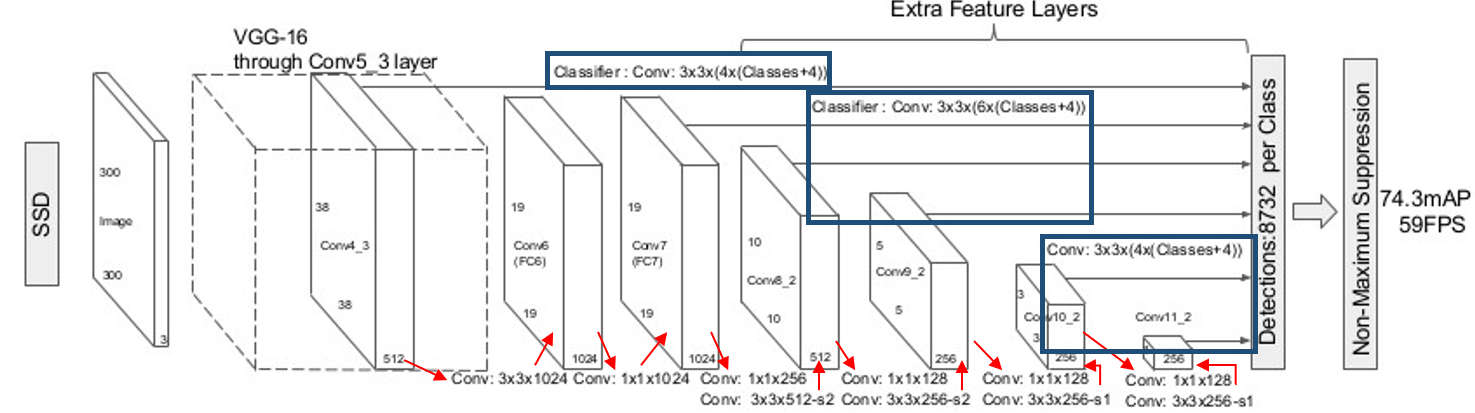
- Base network : VGG-16[5]
- Conv 4_3, 7, 6_2, 9_2, 10_2, 11_2을 입력으로 컨벌루션하여 6개의 특징맵 생성
- 특징맵에는 경계박스(x, y, w, h)와 클래스 정보(Classification)가 저장됨
- Conv 4_3 : 3838(4(Classes+4)) = 5776(Classes+4)
- Conv 7(FC7) : 1919(6(Classes+4)) = 2166(Classes+4)
- Conv 8_2 : 1010(6(Classes+4)) = 600(Classes+4)
- Conv 9_2 : 55(6(Classes+4)) = 150(Classes+4) = 클래스당 8732개의 경계박스를 예측
- Conv 10_2 : 33(4(Classes+4)) = 36(Classes+4)
- Conv 11_2 : 11(4(Classes+4)) = 4(Classes+4)

- SSD는 Faster R-CNN에서 사용하는 Anchor box와 비슷한 Default Box 사용
- 기본적으로 가로/세로 로 계산되는 종횡비를 사용
- 4* : 1, 2, 1/2, 종횡비가 1인 크기가 작은 박스 사용
- 6* : 1, 2, 3, 1/2, 1/3, 종횡비가 1인 크기가 작은 박스 사용
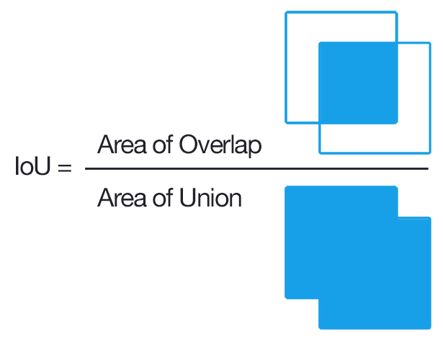
- IoU로 정의되는 Jaccard overlap이 50% 이상이 되는 모든 디폴트 박스들 학습
-
특징맵의 각 Grid cell의 경계박스들과 정답과의 Jaccard overlap이 가장 큰 곳 학습
- Jaccard overlap(IoU) 계산 방법
- $s_{k}=s_{min}+\frac{s_{max}-s_{min}}{m-1}(k-1)$, $k\in[1,m]$
- Jaccard overlap 계산을 위해 스케일 계수 $s_k$를 이용하여 디폴드 박스 가로/세로를 구함.
- $a_{r}\in{{ {1, 2, 3, \frac{1}{2}, \frac{1}{3}}}}$
- $\left( {w_k^a=s_k\sqrt{a_r}} \right)$
- $\left( {h_k^a=\frac{s_k}{\sqrt{a_r}}} \right)$
- 위 공식을 이용하여 넓이가 1인 디폴드 박스의 가로, 세로 길이를 정의
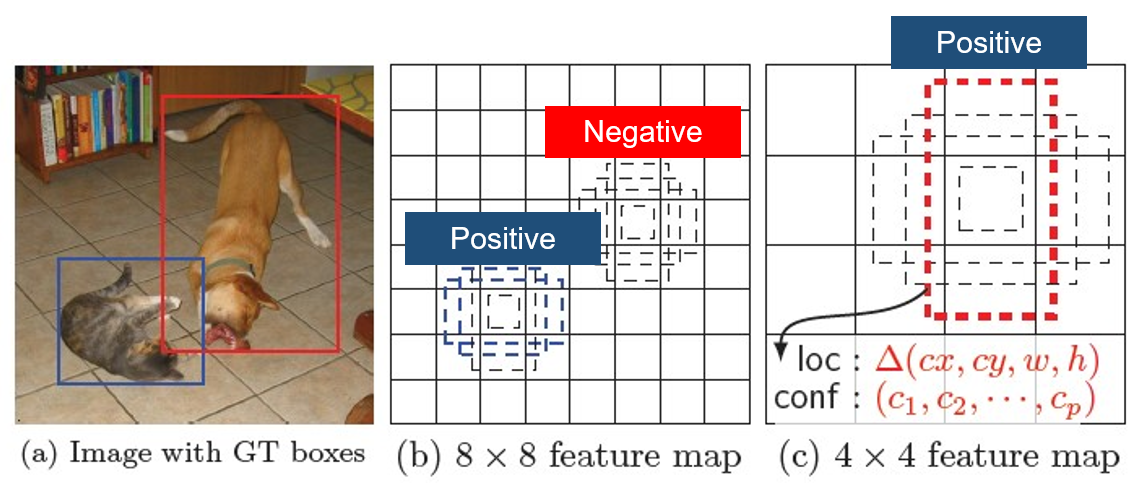
- 예측 된 경계박스의 Positive : Negative = 1 : 3 비율
- 객체에 대한 Confidence loss가 큰 것 만을 골라 loss를 줄이는 방향으로 학습
SSD Loss function
- $L(x, c, l, g)=\frac{1}{N}(L_{conf}(x, c)+\alpha L_{loc}(x, l, g))$
- Loss function은 객체에 대한 confidence와 경계박스에 대한 localization을 더한 형태
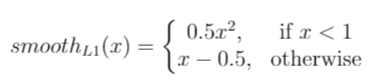
- $\hat{g}^{cx}_j=(g^{cx}_j-d^{cx}_i)/d^w_i \qquad \hat{g}^{cy}_j=(g^{cy}_j-d^{cy}_i)/d^h_i$
- $\hat{g}^w_j=log(\frac{g^w_j}{d^w_i}) \qquad \hat{g}^h_j=log(\frac{g^h_j}{d^h_i})$
- $N$: 검출된 박스 개수
- $g$ : ground truth box (실제 박스의 변수들)
- $d$ : default box
- $c$ : category
- $l$ : predicted boxes (예상된 박스의 변수들)
- $cx$, $cy$ : offset of center
- $w, h$ : width and height
- $\alpha$ : weight term( $\alpha$ = 1)
- The confidence loss is the softmax loss over multiple classes confidences ($c$).
- The weight term $\alpha$ is set to 1 by cross validation.
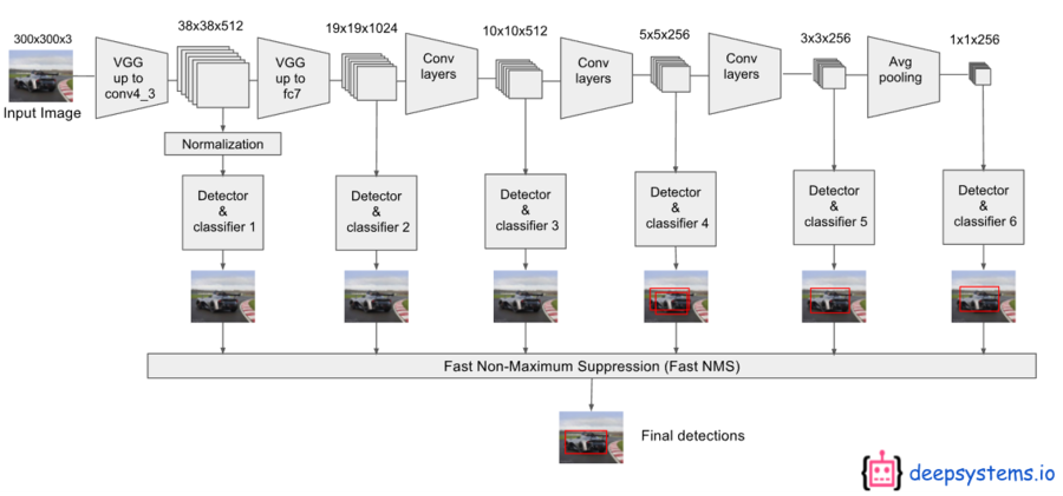
-
Fast NMS를 사용하여 6개의 Classifier의 예측 중 신뢰도가 가장 큰 것 하나만을 남기고 나머지는 모두 지움
-
ex. Conv 9_2 : 55(3(Classes+4)) = 150(Classes+4)
- 원래는 Conv 9_2 : 55(
6(Classes+4)) = 150(Classes+4)이나, 예시를 위해3으로 함
- 원래는 Conv 9_2 : 55(
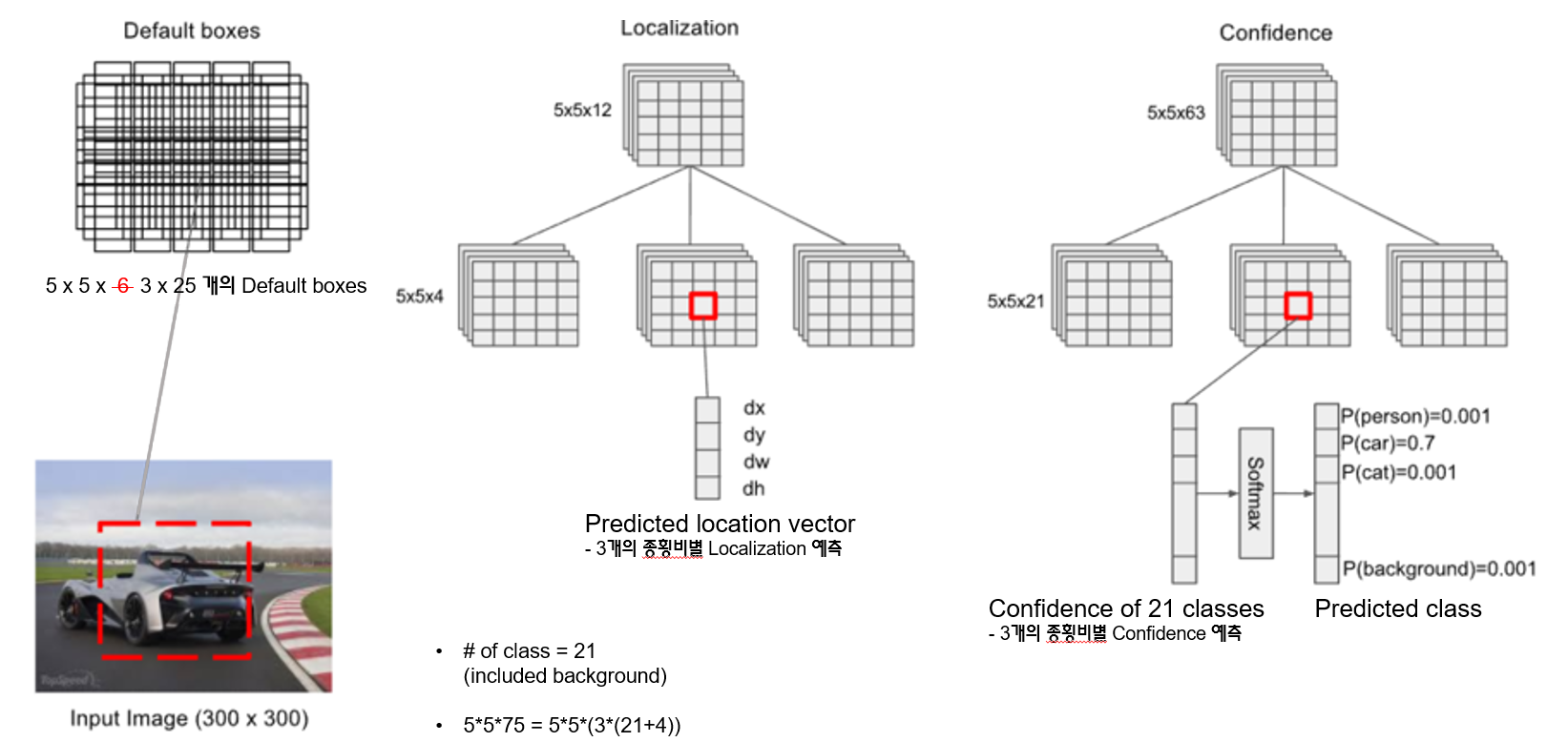
- 21개의 클래스가 있는 경우, 위와 같이 553=75의 특징맵에 대해 55(3(21+4))로 55의 그리드 각각 셀에서 경계박스와 클래스 확률 3개씩을 예측함(75=25*3)
- 출력은 21개의 클래스에 대한 신뢰도

- 이렇게 생성된 75개의 경계박스 중 신뢰도 점수가 0.01보다 높은 것만 남기면 대부분의 경계박스는 사라짐.
- 검출된 75개의 경게박스에 대한 confidence에 의한 필터링
Experimental Result of SSD
- Base network
- VGG16 (with fc6 and fc7 converted to conv layers and pool5 from 2x2 to 3x3 using atrous algorithm, removed fc8 and dropout)
- It is fine-tuned using SGD
- Training and testing code is built on Caffe toolkit
- Database ‘07
- Training: VOC2007 trainval and VOC2012 trainval (16551 images)
- Testing: VOC2007 test (4952 images)
- Database ‘12
- Training: VOC2007 trainval, test and VOC2012 trainval(21503 images)
- Testing: VOC2012 test(10991 images)
- Mean Average Precision of PASCAL VOC 2007

- Mean Average Precision of PASCAL VOC 2012

- Inference time 비교
- Non-maximum suppression 알고리즘에 대한 효율성 개선의 여지가 남아있음
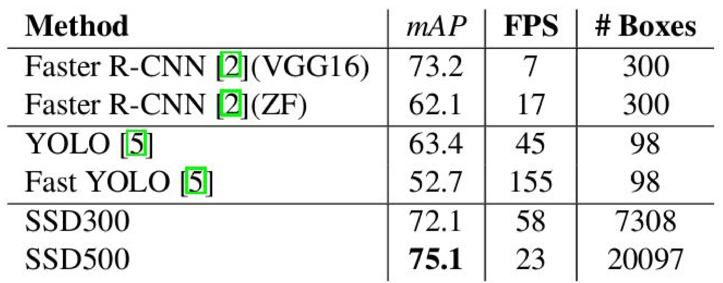
- Visualization

- [원문 출처]
https://seongkyun.github.io/papers/2019/01/06/Object_detection/
- [참고 글]
[1] Ross Girshick, “Rich feature hierarchies for accurate object detection and semantic segmentation”, 2013
[2] Ross Girshick, “Fast R-CNN”, 2015
[3] Shaoqing Ren, “Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks”, 2015
[4] Wei Liu, “SSD: Single Shot MultiBox Detector”, 2015
[5] Karen Simonyan, “Very Deep Convolutional Networks for Large-Scale Image Recognition”, 2014