
 Hyojin Kim's blog
Hyojin Kim's blog
K-fold 개념과 Stratified cross validation 적용해보기
02 Apr 2020 | Deep learning K-foldK-fold
개념
데이터를 k개의 분할(k개의 fold, 일반적으로 k=4 or 5)로 나누고 k개의 모델을 만들어 k-1개의 분할에서 훈련하고 나머지 분할에서 평가하는 방법이다. 모델의 검증 점수(score)는 k개의 검증 점수의 평균이 된다.
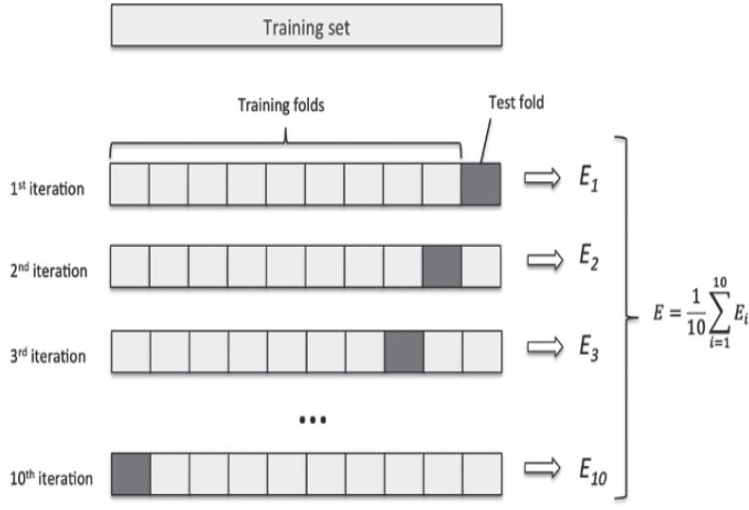
k개의 검증 점수의 평균을 구하는 방법
- 모든 폴드에 대해 epoch의 평균 절대 오차인 MAE(Mean Absolute Error)의 오차 평균을 구하면 된다.
- Validation MAE(y축), Epochs(x축)을 갖는 그래프를 그려보고 그래프의 흐름을 보면, 어디서 과대 적합이 일어났는지 체크할 수 있다.
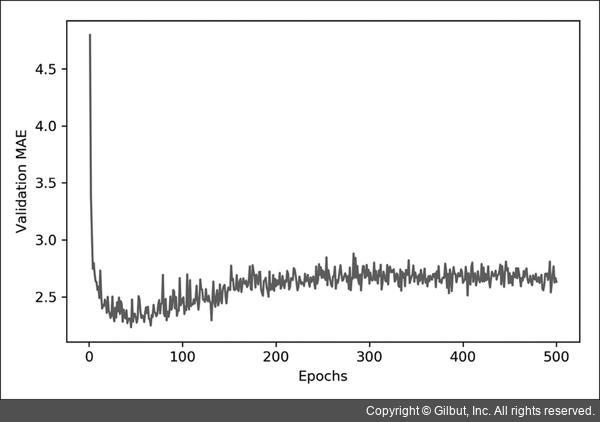
딥러닝에서 k fold를 쓰면 어떤 효과가 있을까?
- 데이터 검증 세트의 분할에 따른 검증 결과를 보고 어떤 데이터 세트가 과대적합 일으켰는지를 확인 할 수 있다.
- 따라서 과대적합(overfitting)을 막는다는 의의가 있다.
- 공부한 책에서는 예시로 100epoch별 검증 점수를 보고 어떻게 epoch을 구성해야할지 알 수 있었다.
- 이런 방식으로 kfold를 쓰면 어느 지점에서 학습이 덜되는지 더 되는지 알수 있으니까 파라미터 값을 조절할 수 있다는데 의의가 있다.
여기서 잠깐!
k fold를 쓰면 validation set 도 트레이닝하게 되어서 정확한 acc?같은걸 체크하기가 애매해지지 않을까?
- 그래서 validation set은 따로 나눠놓고 train set에서만 쓴다. 즉, Train set안에서 kfold를 진행하는 방식인 것이다.
Stratified cross validation
개념
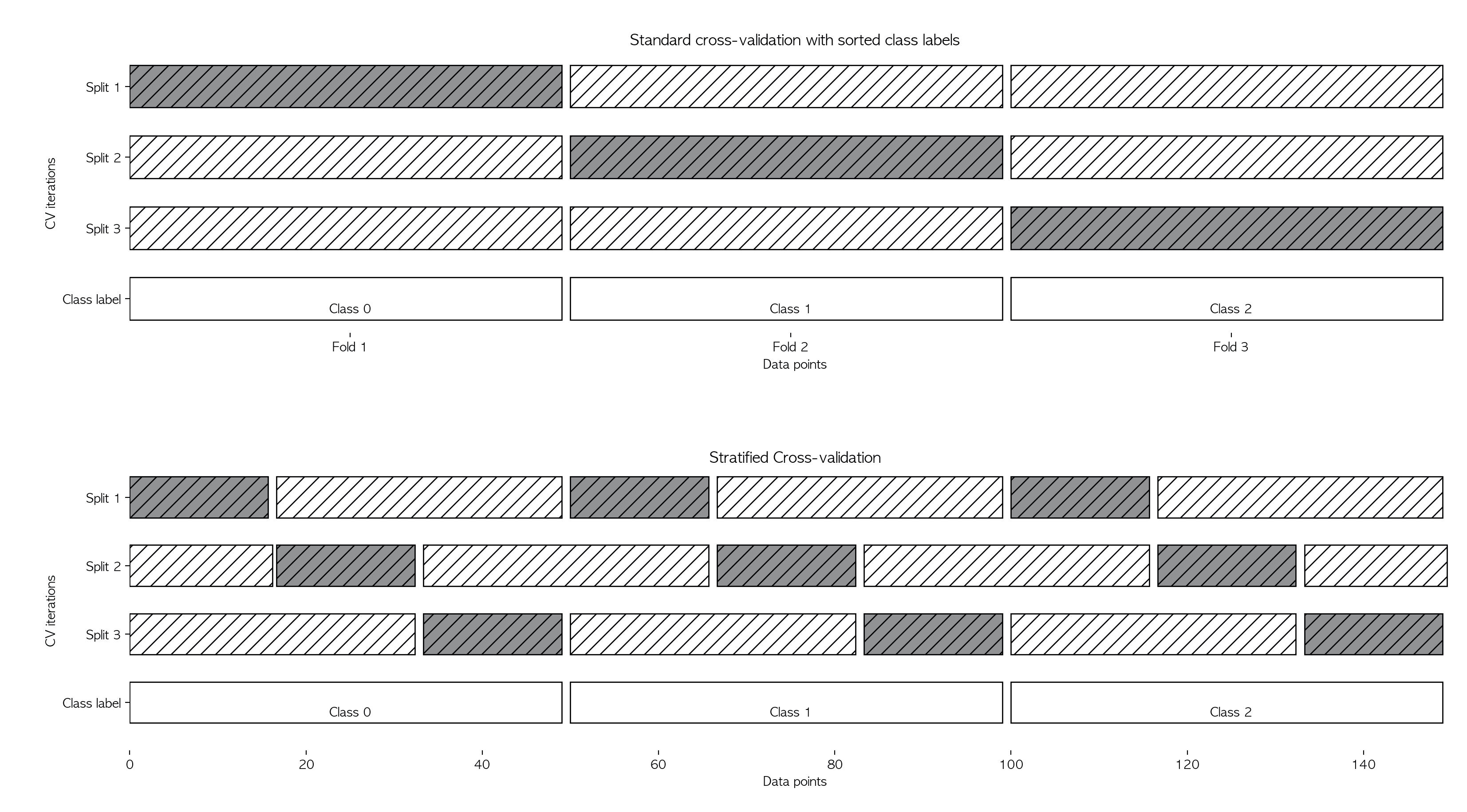
데이터가 편항되어 있을 경우(몰려있을 경우) 단순 k-겹 교차검증을 사용하면 성능 평가가 잘 되지 않을 수 있다. 따라서 이럴 땐 stratified k-fold cross-validation을 사용한다
StratifiedKFold 함수는 매개변수로 n_splits, shuffle, random_state를 가진다. n_splits은 몇 개로 분할할지를 정하는 매개변수이고, shuffle의 기본값 False 대신 True를 넣으면 Fold를 나누기 전에 무작위로 섞는다. 그 후, cross_val_score함수의 cv 매개변수에 넣으면 된다.
★ 참고!
일반적으로 회귀에는 기본 k-겹 교차검증을 사용하고, 분류에는 StratifiedKFold를 사용한다.
또한, cross_val_score 함수에는 KFold의 매개변수를 제어할 수가 없으므로, 따로 KFold 객체를 만들고 매개변수를 조정한 다음에 cross_val_score의 cv 매개변수에 넣어야 한다.
코드로 적용해보기
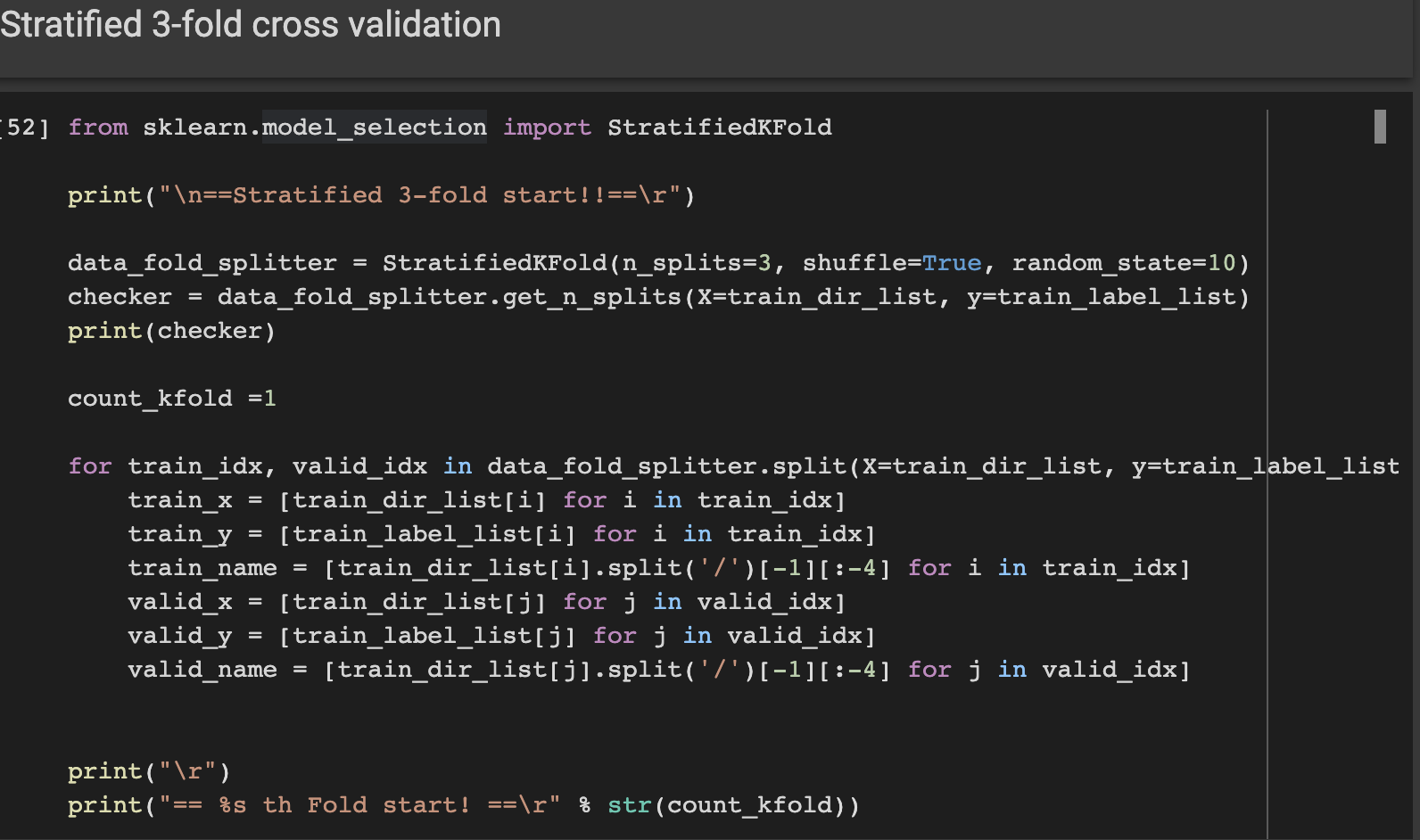
- 시도1. 경로를 pathlib으로 받아서 list에 넣고, split시도 -> 실패

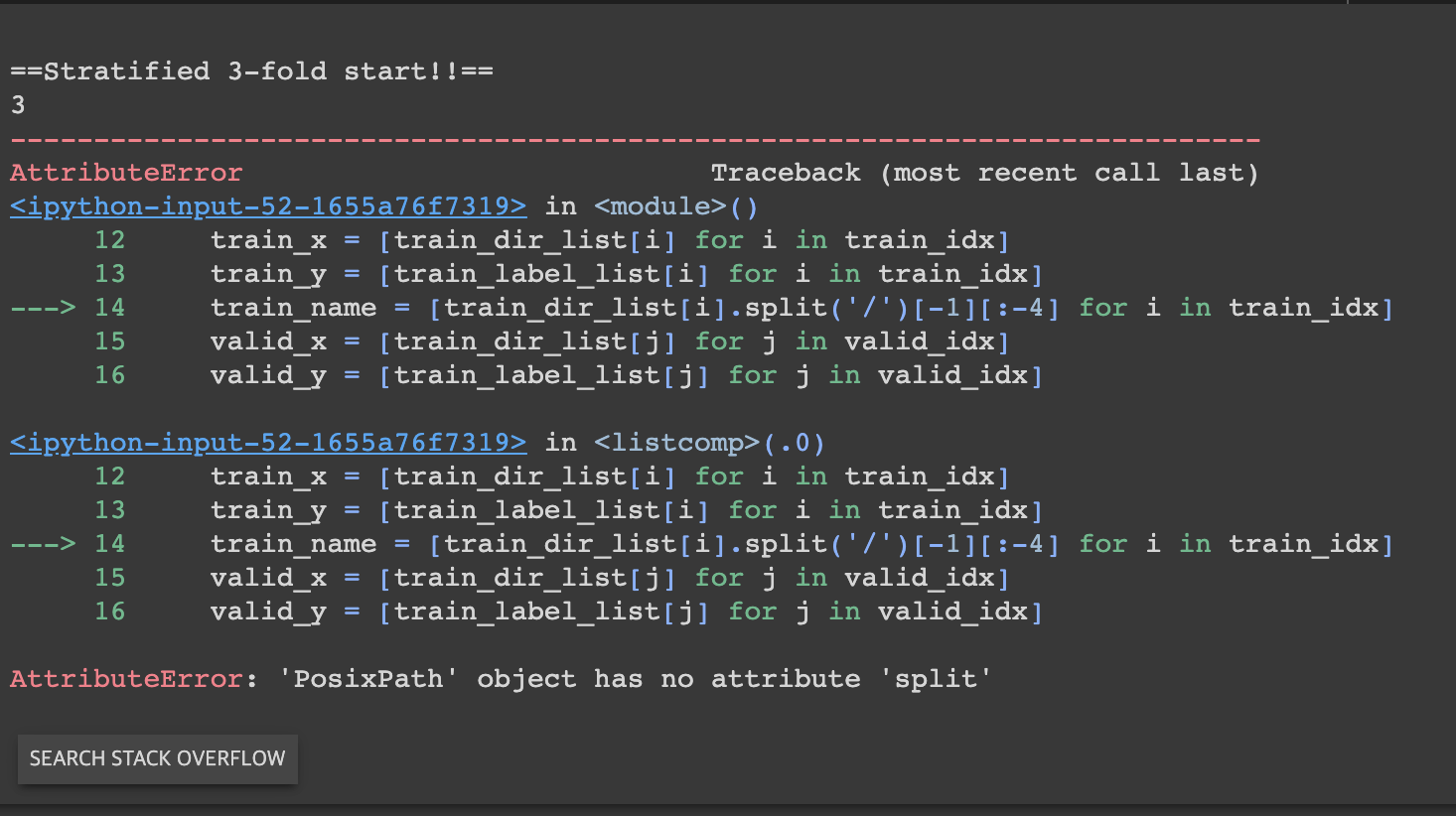
- 시도2. str.split 시도 -> 실패
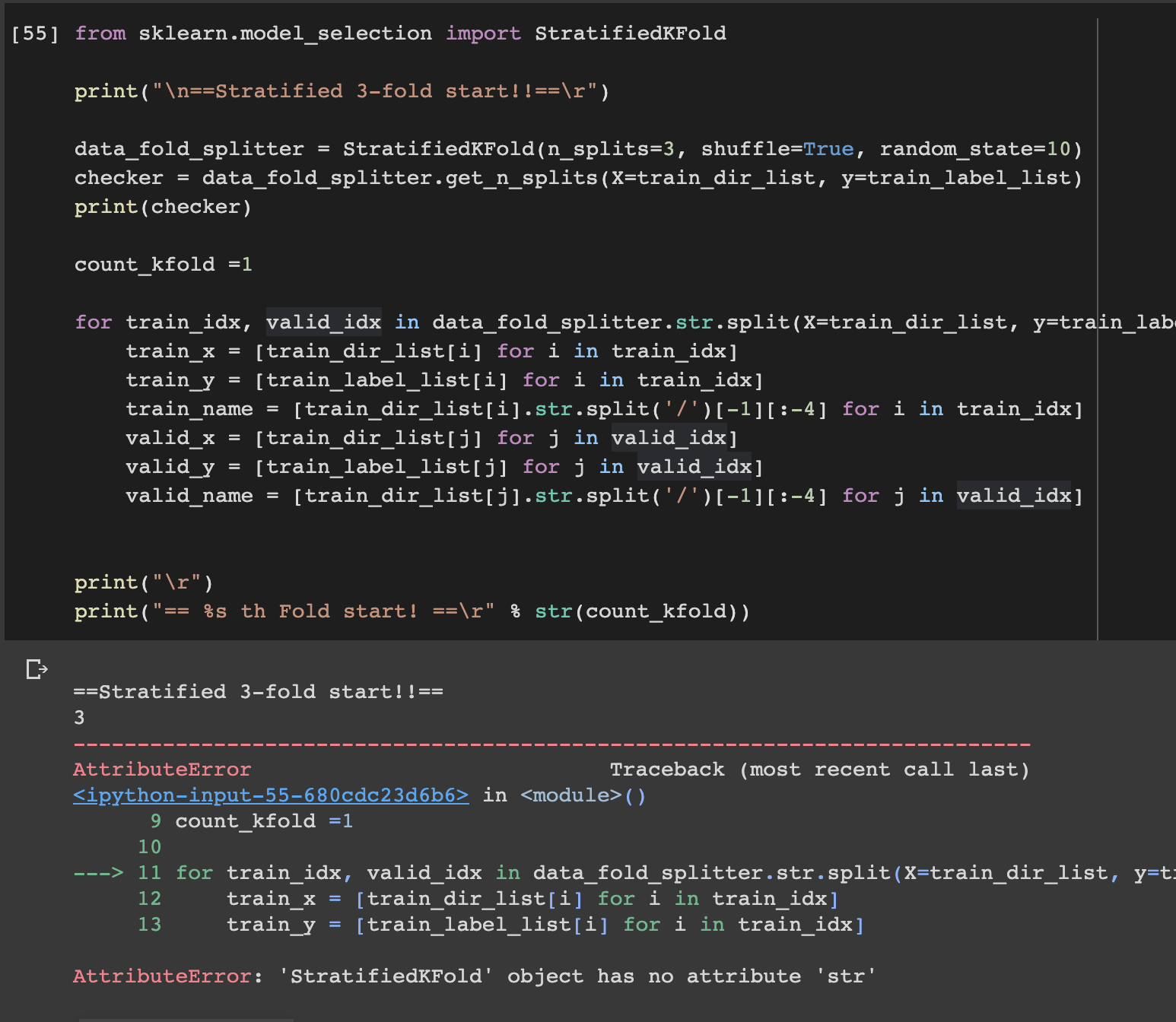
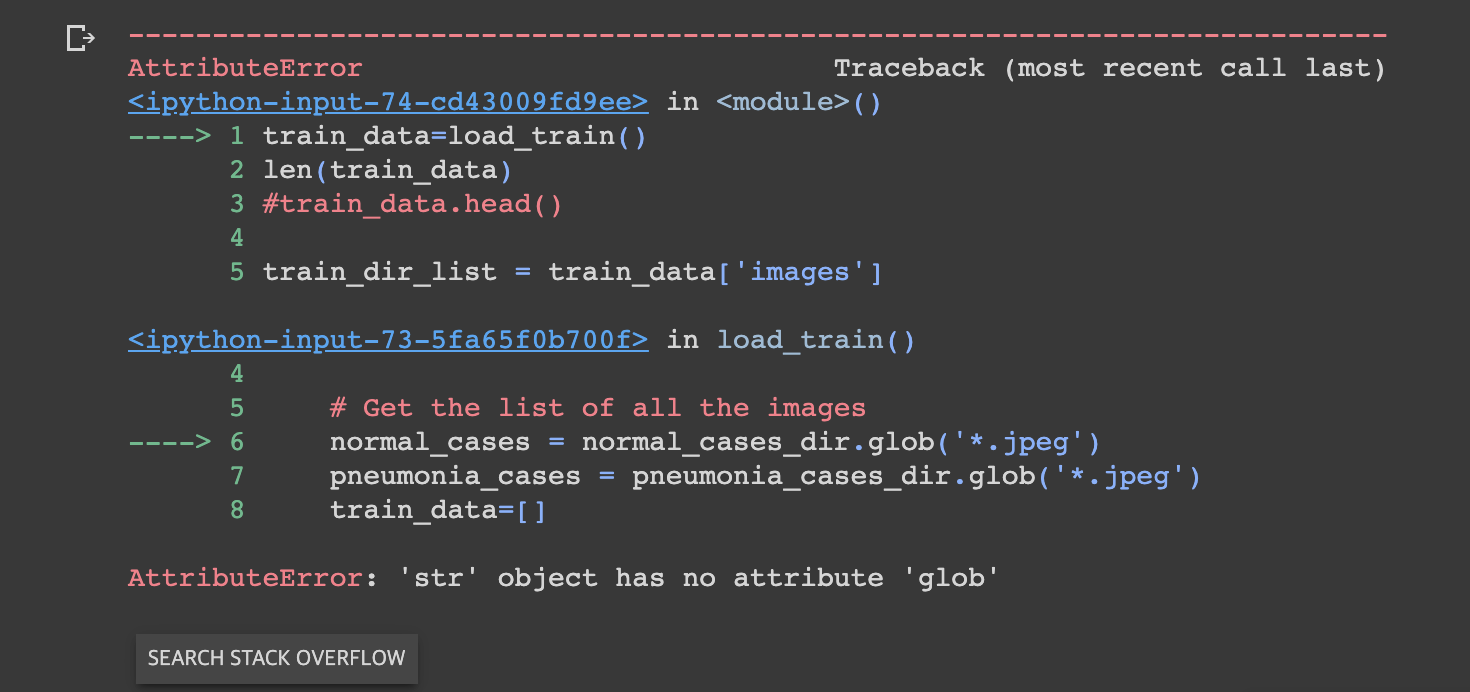
- 시도3. 경로를 string으로 받아서 split시도 -> glob모듈에서 오류가 남 -> 실패

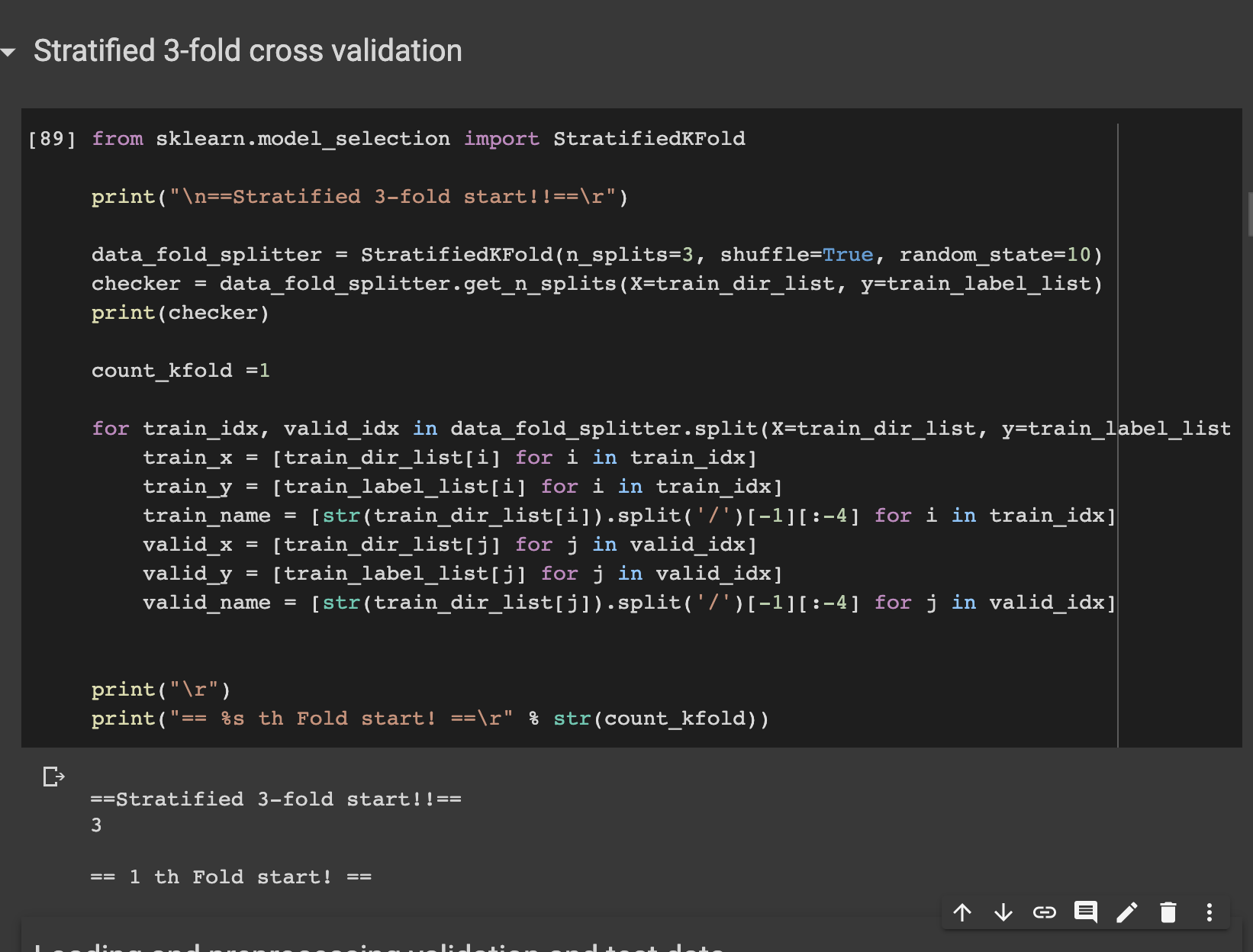
- 시도4. 다시 경로를 pathlib으로 받고 split하는 전체 덩어리에 str()로 형변환 -> 성공!
시행착오 후, 고찰
- pathlib으로 받은 경로는 객체로 저장된다.
- split은 문자열을 나누는 함수이기 때문에 당연히 string 형태로 받아야 한다.
- glob에 string 타입의 디렉토리를 넣어도 된다고 하는데 왜 안됐던 거지?
다음으로 해야할 것
- 경로를 설정 후 데이터를 cross validation했으니, 그 다음에는 무엇을 해야할까?
- 모델학습 fit 시키고 검증 점수(에포크별 검증 MAE)를 로그에 저장하게끔 하면 되는 걸까?
- 공부한 내용으로는 k-fold하고 검증 mae(평균 절대 오차: 예측값과 기존의 값인 타겟값 사이의 절대값)를 뽑던데, 이와 같이 진행되는건지 아니면 달리 진행하는 건지 궁금하다.