 Hyojin Kim's blog
Hyojin Kim's blog
200307 TIL
07 Mar 2020 | TILToday, what I did
- 랩미팅
Today, what I realized
- 랩미팅 후에 푹 쉬어야겠다
Tommorow’s work
- 피피티 정리해서 블로그에 포스트하기

이 논문은 2016년 CVPR에 실린 “Learning Deep Features for Discriminative Localization”의 Visualization 방법인 CAM(Class Activation Map)입니다.
CAM 논문을 리뷰하게 된 이유는 Region Proposal Network와 Weakly supervised learning을 알아보고 싶었기 때문입니다. 저번 시간에 r-cnn을 비롯한 detection 시리즈를 봤고 같은 흐름을 가졌지만 다른 학습 방법으로 객체를 검출하는 논문을 다뤄보고 싶었습니다. 이에 Weakly supervised learning object detection의 가장 근간이 되는 CAM 논문을 리뷰하고자 합니다.

Bounding box를 input으로 주지 않아도, object detection 용도로 학습된 모델을 조금만 튜닝하면 object detection이 가능합니다. 하지만 분류를 위해 fully connected layer를 사용함으로서 이 기능이 사라집니다. Network In Network(이하 NIN)나 GoogLeNet에서는 파라미터 수 최소화를 위해 fully connected 대신 Global Average Pooling(이하 GAP)을 썼습니다. 이 GAP은 파라미터 수를 줄여 오버피팅을 방지하는 기능 외에도, 오브젝트의 위치 정보를 보존하는데 사용할 수 있습니다. GAP를 통해 특정 클래스에 반응하는 영역을 맵핑하는 Class Activation Mapping(이하 CAM)을 제안합니다.
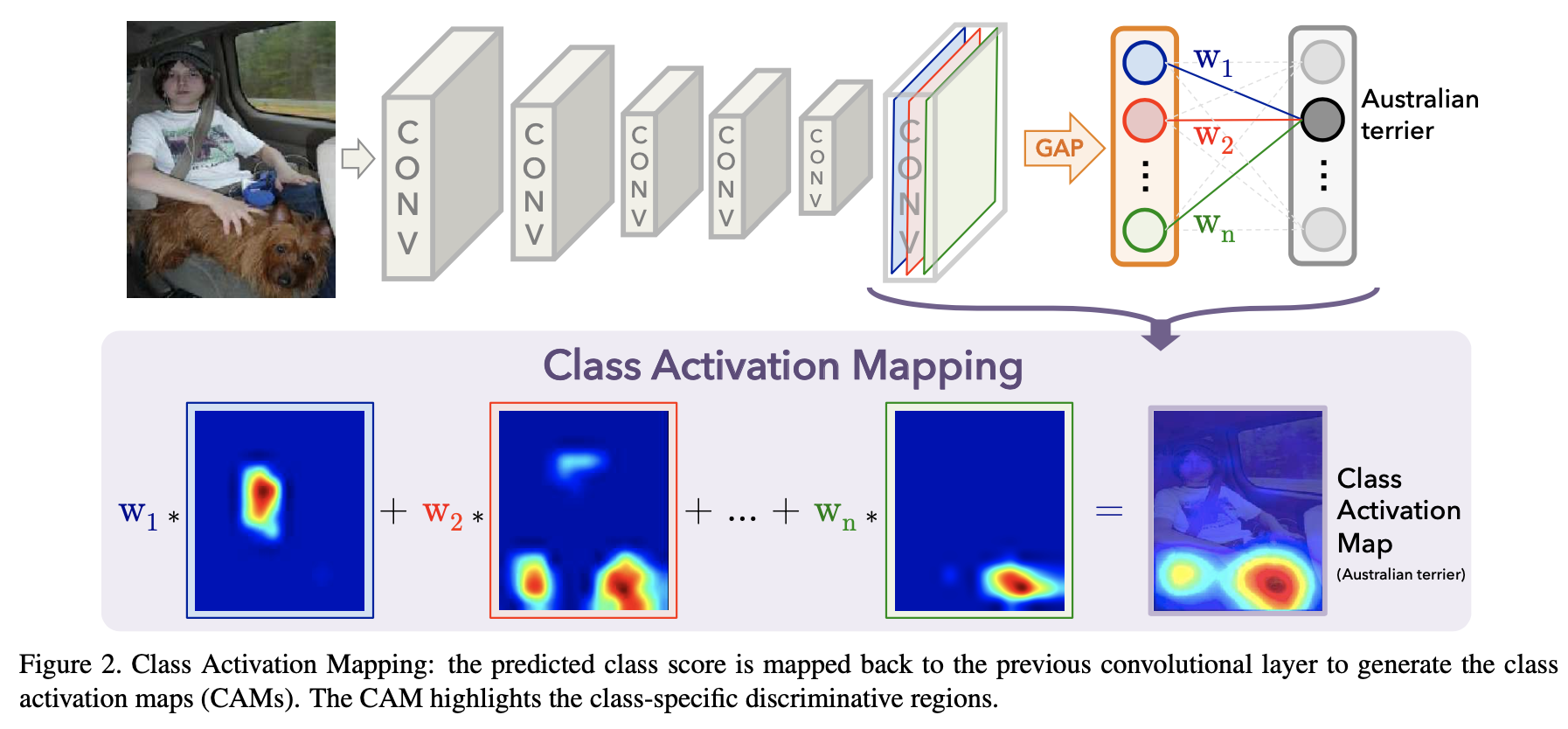
당시 제안된 다른 위치 추적 방식들은 selective search를 통해 bounding box를 그려서 클래스를 분류했습니다. 하지만, CAM은 GAP을 통과시켜서 한번에 (single forward pass) end-to-end로 학습할 수 있게 됩니다. 또한 GAP을 max, average pooling의 용도로 사용한 것이 아니라 네트워크를 정의하는데 사용했다는 점에서 의의가 있습니다.
당시 feature map을 확인하는 방식들은 Deconvolutional Neural Network를 통해 각각의 CNN unit에서 어떤 부분에서 이미지가 활성화 되었는지 알 수 있었습니다. 하지만, 이 논문에서 제안한 방식에서는 FC를 사용하지 않아도 CAM연산을 통해 어떤 부분의 이미지가 활성화 되었는지 알 수 있습니다.
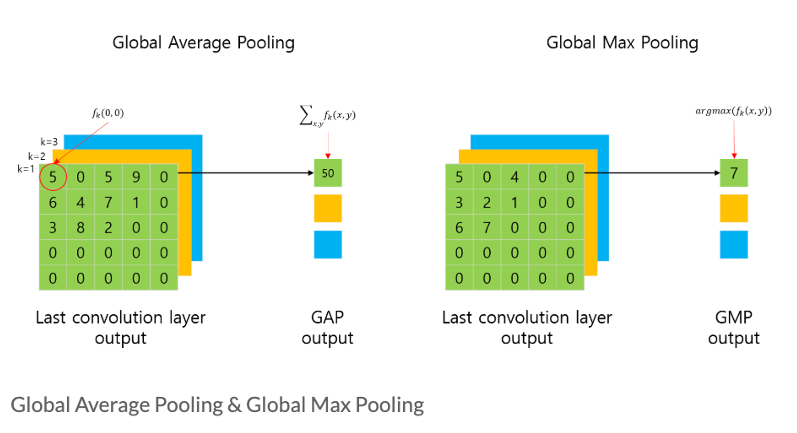
또한, GMP(Global Max Pooling)은 탐지 사물을 포인트로만 짚는 반면, GAP는 사물의 위치를 전체 범위로 잡습니다. 위치정보를 잃지 않기 위해선 둘 다 써도 무방하지만 GAP이 더 좋은 시각화 결과를 내기 때문에 해당 논문에서는 GAP을 썼고, 더불어 최근 논문에서도 GAP을 더 많이 쓰는 추세입니다.
전역적으로(Global) Average Pooling을 수행하는 layer 입니다. 또한, 일반적인 pooling layer가 max 연산을 가지고 있듯이, GMP(Global Max Pooling)도 있습니다. 마찬가지로, 전역적으로 Max Pooling을 수행하는 layer를 의미합니다.
사실, GAP 연산은 평균(Average)을 취해야 하는게 맞지만, 논문에서 표현한 수식과 혼동하지 않기 위해서 평균값을 취하지 않았습니다.
그림에서 표현된 것처럼 fk(0,0)은 CNN의 feature map의 0,0 번째에 해당하는 요소의 값을 의미합니다. GAP나 GMP의 연산 결과는 그림과 같이 각 채널별로 하나의 값이 나오게 됩니다. 즉, 이전 5x5 feature map의 채널이 3개였다면, feature map의 크기와 상관없이, 채널의 개수에 해당하는 3개의 값(1x1)이 출력됩니다.
이러한 GAP layer는 fc layer와 달리 연산이 필요한 파라미터 수를 크게 줄일 수 있으며, 결과적으로 regularizer와 유사한 동작을 해서 과적합을 방지할 수 있습니다. fc layer에서는 Convolution layer에서 유지하던 위치 정보가 손실되는 반면, GAP나 GMP layer에서는 유지할 수 있습니다[2].
이번에 다루는 논문에서는 이러한 GAP와 GMP의 특성을 기반으로, 클래스에 따라 CNN이 주목하고 있는 영역이 어떤 부분인지 시각화하는 방법인 CAM(Class Activation Map) 제안하고 있으며, 이러한 시각화 방법은 Object Localization 으로도 활용될 수 있다고 합니다. 즉, 일반적인 Image Classification을 위해 Weakly-supervised로 학습된 CNN으로도 Image Localization을 할 수 있다는 의미입니다. 그럼 Class Activation Map이 무엇인지 살펴봅시다.
먼저 GAP를 사용하는 CNN 아키텍쳐의 구조를 살펴보면 다음 그림과 같이 요약할 수 있습니다.
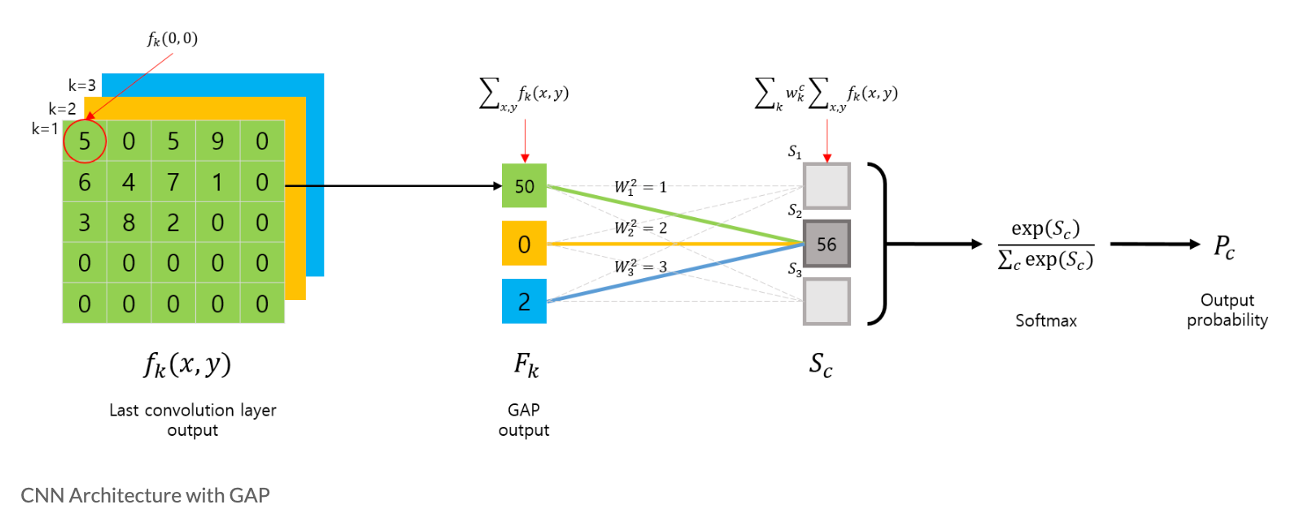
먼저 마지막 Convolution layer 에서 출력된 feature map 는 GAP 연산이 취해지며 k개의 값이 출력됩니다.

이후 GAP의 출력은 CNN의 마지막 출력 layer인 로 전달되면서 linear combination(weighted sum)을 수행합니다.
이렇게 계산된 는 Softmax layer를 거처, 최종 출력을 만듭니다.
CAM은 위의 를 도출하기 위한 수식을 살짝 변경해서, 다음과 수식과 같이 클래스 에 대한 Map 을 구합니다.
위 수식의 도출 과정을 그림으로 표현하면 다음 그림과 같이 표현될 수 있습니다.
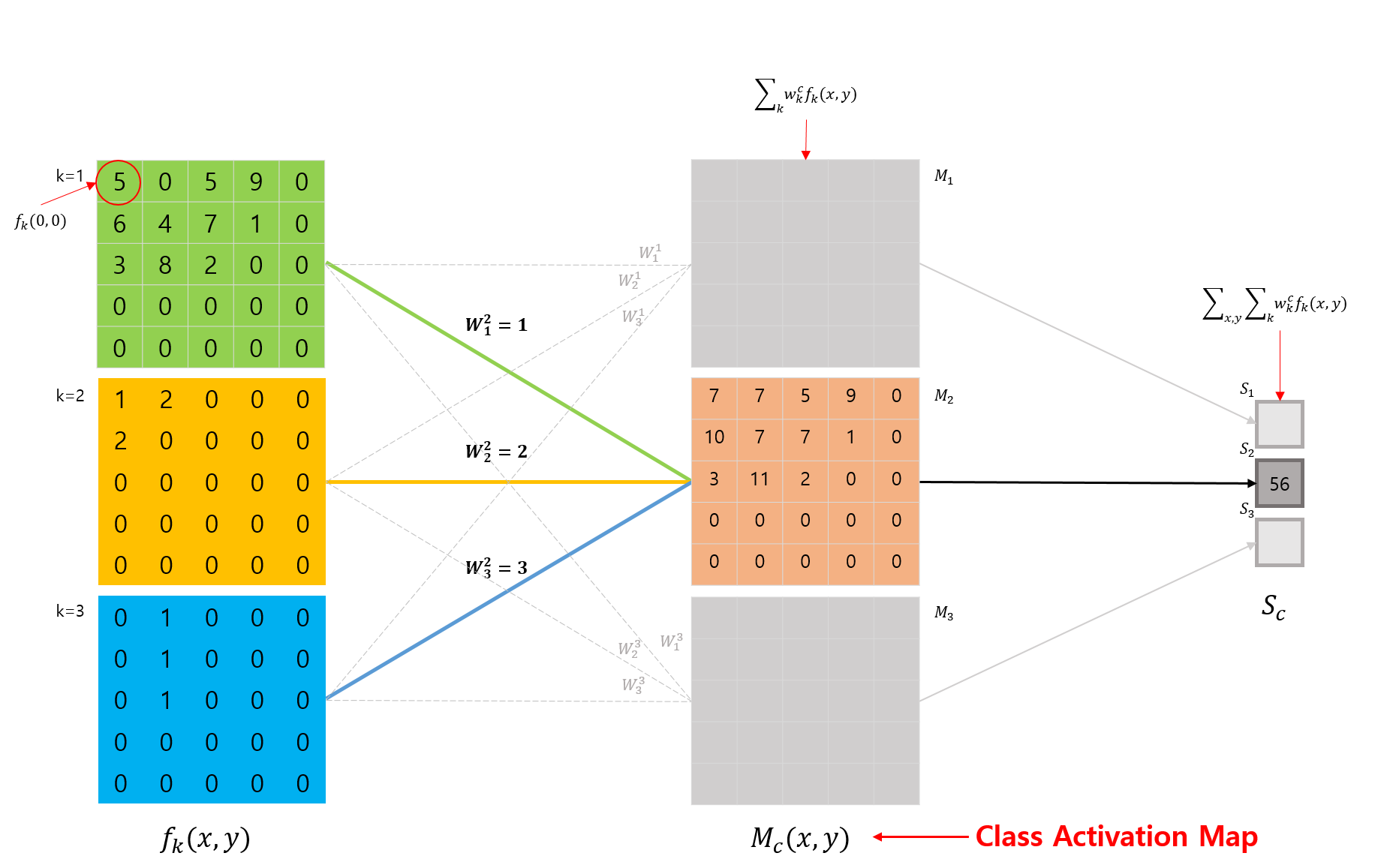
수식을 이해하기 위해 CAM이 어떤 동작을 하는지 다시한번 확인해봅시다. CAM은 특정 클래스 를 구별하기위해 CNN이 어떤 영역을 주목하고 있는지 시각화하는 방법입니다.
2번째 그림(CNN Architecture with GAP)을 예로 들면, 특정 클래스 를 구별하기 위해 이 클래스에 연결된 weights 와 각 feature map에 대해 linear combination(weighted sum)을 취한 결과가 바로 CAM입니다.
위의 그림(Class Activation Map)을 통해서 확인해보면, 를 구하는 수식에서, GAP에 사용되었던 feature map에 대한 평균(논문에서는 합)만 제외한 것입니다.
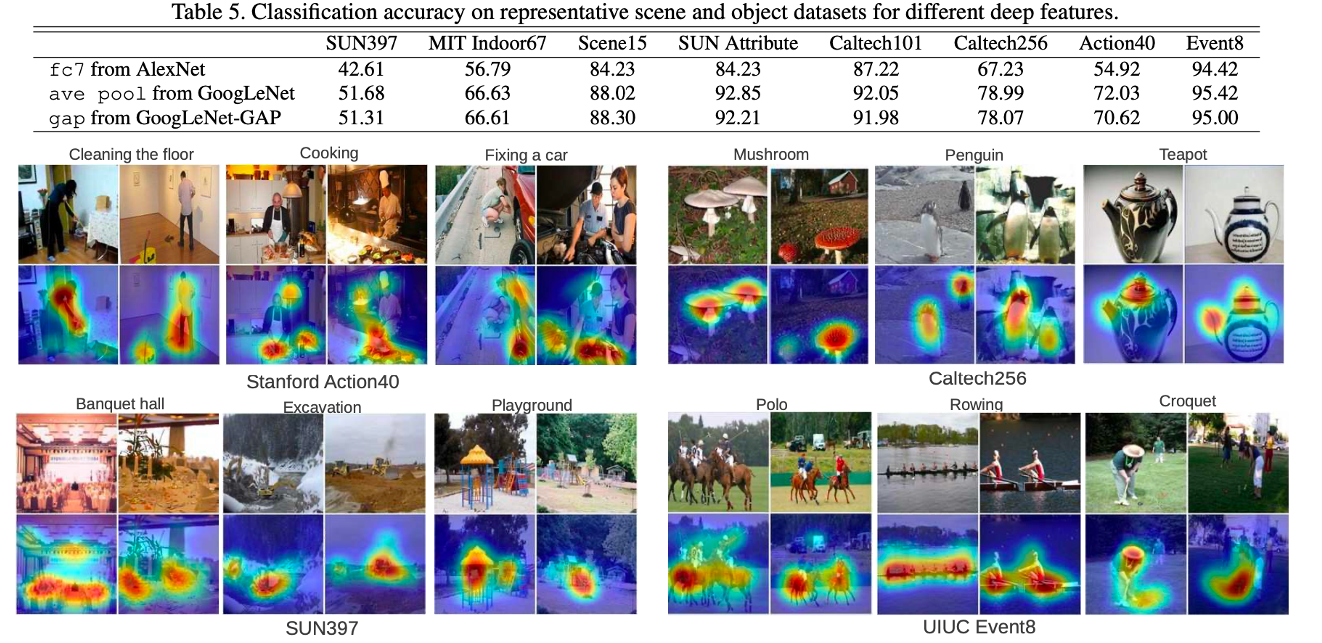
연산이 필요한 파라미터 수를 크게 줄일 수 있게 되었고, 이에 연산량을 낮췄음에도 불구하고 다른 모델과 유사한 성능을 보였습니다. 가장 핵심적인 내용으로는 이와 같습니다.
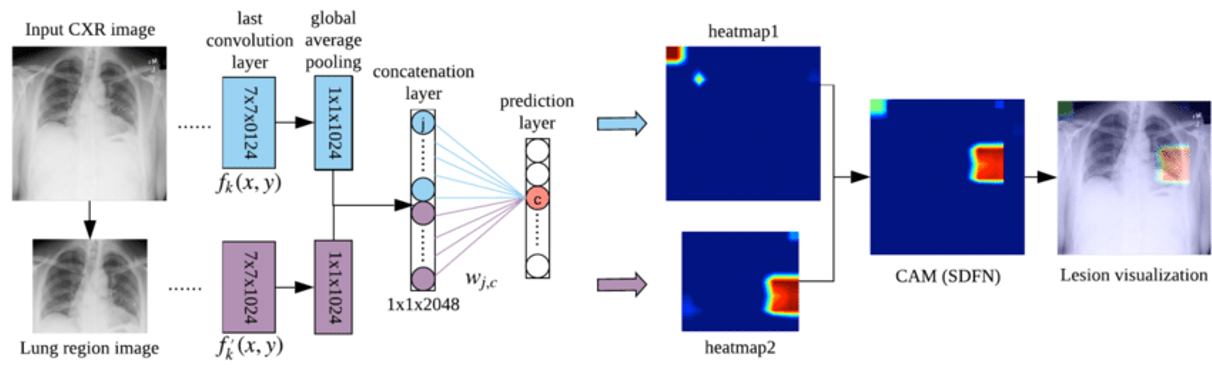
CAM을 활용하여 다양한 의료병변을 검출하는 논문이 많이 나왔습니다. SDFN: Segmentation-based Deep Fusion Network for Thoracic Disease Classification in Chest X-ray Images[3]은 CAM을 활용하여 흉부 질병의 위치를 검출하는 방법을 보여줍니다.
[1] Learning Deep Features for Discriminative Localization, 2016 [paper]
[2] Object detectors emerge in deep scene cnns [paper]
[3] Segmentation-based Deep Fusion Network for Thoracic Disease Classification in Chest X-ray Images [paper]
https://kangbk0120.github.io/articles/2018-02/cam
https://you359.github.io/cnn%20visualization/CAM/